Dr. Suchi Saria discusses the development and outcomes of her early sepsis warning system, TREWS, and a call to action for industry experts and policymakers in this TEDx talk.
Watch the TedTalk here.
Dr. Suchi Saria discusses the development and outcomes of her early sepsis warning system, TREWS, and a call to action for industry experts and policymakers in this TEDx talk.
Watch the TedTalk here.
Dr. Suchi Saria shares her journey bringing machine learning to the bedside, overcoming barriers, and creating practical applications that impact real patients.
Watch the TedMed talk here.
Dr. Suchi Saria joins a panel of fellow industry experts to discuss artificial intelligence as the single biggest opportunity in healthcare today, and it’s capacity to shift reactive care to proactive care.
See the full panel here.
Dr. Suchi Saria discusses her journey working with a multidisciplinary team to successfully deploy artificial intelligence at the bedside, create actionable alerts, and improve patient outcomes.
See the full workshop here.
A targeted real-time early warning score (TREWScore) for septic shock
Sepsis is a leading cause of death, contributing to 1 in every 2 or 3 hospital deaths. Early identification and treatment has a dramatic impact on morbidity and mortality. In a cover article published in Science Translational Medicine, Dr. Saria and colleagues showed that routinely available vital signs and lab results could be used to predict which patients would experience septic shock. TREWScore (Targeted Real-Time Early Warning Score) was more accurate than a routine screening protocol and another score used clinically for predicting septic shock (MEWS). TREWScore identified patients 28.2 hours (median) before onset with ⅔ of cases identified before any sepsis-related organ dysfunction.
This was the first study to show that applying machine learning techniques to clinical data could be used to proactively identify patients at risk of sepsis. Since then, over 200 related papers have been published.
Read the full research paper here.
Today, Bayesian Health exited stealth mode, bringing to market its research-backed AI platform that helps health systems deliver safer and higher quality care. But we’ve been at it for much longer—we’ve been heads down, working as a company for more than three years.
Why did we wait so long to launch?
It was important for us to come to market with a research-first and outcome driven approach. There are so many technologies out there that don’t deliver on their promises or haven’t been evaluated to see the true outcome and impact of the tool. AI and machine learning technology and strategies are moving at such a fast pace, and health data are innately messy. To do it right, it requires deep AI expertise to deliver strategies that can successfully analyze this data. But perhaps what’s even harder is what happens after the model is created; even with great models, you still need the solution to be adopted and trusted to realize better outcomes.
Over the past three years, we’ve operationalized decades of leading AI/machine learning research into a software, deployed it, and measured outcomes. And we’re publishing these outcomes and methods for transparency, to inspire confidence and trust amongst physicians, clinicians, care team members and informaticists. It is incredibly important to create tools that not only have great models, but have also earned the trust — and regular use — of those who engage (and will engage) with the platform daily.
Our purposeful deployment process included building, testing, learning, and iterating, in order to create a solution that worked both on the backend and front end. The development process culminated in a two-part, multi-site outcome study validating the platform. We released the first part of the study today.
What did this first study show?
A large, five site study analyzing use and practice impact over two years for Bayesian Health’s sepsis module showed high sensitivity (80%+) with high precision (1 in 3 alerts were provider confirmed). Sepsis is a needle in a haystack problem, so it’s hard to achieve high precision at high sensitivity, and especially harder where you’re also optimizing for earlier detection times. But all three of these things are critical to cracking the code on earlier sepsis recognition and prevention.
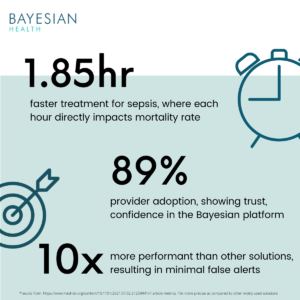
Our high quality, timely clinical signals resulted in 1.85 hour faster life-saving patient treatment driven by high provider adoption (89%).
With research showing the average adoption of clinical decision support tools to be low, our high adoption is exciting news, and shows physician confidence and trust in the Bayesian insights, leading to proactive, earlier care. This is great news for patient outcomes, where for sepsis every hour of delayed treatment directly impacts mortality rate.
Based on the achieved sensitivity, precision, and timeliness observed in the study, our platform is able to achieve performance that is 10x more precise than any other widely used tool in the market.
We’re really excited by these results — and for the impact our solution will have on patient outcomes. The second part of the study is being finished right now, and we’re even more excited about what the preliminary results say about mortality and overall length of stay reduction.
What’s next?
We’re going to continue to evaluate our solution as we roll out new modules, and work with more health systems and physicians. Because to us, ensuring that our solution is impacting outcomes for the better, driven by high quality real-time clinical signals as well as the user interface and features that allow for trust-building (such as including context with every clinical signal insight), is of critical importance.
We’re doing it differently, and proud to be one of the first solutions to deliver accurate and actionable clinical signals that physicians and nurses trust and act upon. We’re ready to be in the market, and introduce you to our research-backed AI platform.
We’d love to show you how Bayesian’s AI platform can work at your health system.
In order to train high-quality machine learning models, it is essential to be able to determine which samples in the training dataset did (and did not) experience the targeted outcome of interest. Accurate identification of positives and negatives (referred to as “phenotyping”) is particularly challenging in healthcare because there are many confounding data points that can require clinician judgement to interpret, and clinical review is impractical for large-scale datasets. In sepsis, a common method to identify sepsis cases in retrospective datasets is the presence of ICD billing codes. Although billing codes have high precision (low false positive rate), they suffer from low sensitivity (miss many positive cases) and cannot be used to determine sepsis onset time. This study published in Critical Care Explorations describes a new method for sepsis phenotyping that outperforms other automated tools because it accounts for comorbidities that confound other automated tools.
Rigorous definition of targets is one of many strategies Bayesian Health uses to develop best-in-class machine learning models that achieve high sensitivity (80-95%) with 300%-700%+ better precision than many other solutions.
Read the full research paper here.
When building healthcare AI / predictive tools in the real world, certain issues should be considered and accounted for, such as understanding how the tool generalizes from one site to another, how it stands up to changes in physician practice patterns, and how sensitive it is to feedback loops.
In this tutorial, Suchi Saria discusses state of the art research on combining AI and causal inference to build models that are safe and robust in use and practice.
See the full tutorial here.
The Washington Post quoted Dr. Suchi Saria in a discussion about racial bias in machine learning.
Read the full article here.
